Improving memory footprint
In the previous lesson, we have built a simple HTTP server that can accept a file upload from the user and store the file in the server.
You might not noticed any issues when you upload a few of small files to the server. However, when you start increasing the concurrency of the upload or increasing the size of the file, you might start notice that the server is consuming a lot of memory.
This is what happened when I tried to upload 80MB files to the server multiple times:
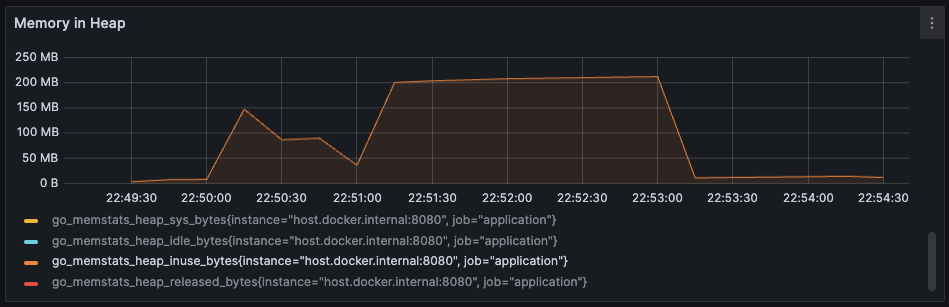
Image above shows the memory consumption of go program running the http server.
As you can see, the memory heap in use increased significantly to 200MB during the duration of the file upload. From here, we can think that the memory usage might be directly proportional to the size of the file being uploaded.
How that can happen? Let’s take a closer look at the code that we have written in the previous lesson:
d, err := io.ReadAll(r.Body)
if err != nil {
log.Error().Err(err).Msg("Error Copying the File")
}
n, err := f.Write(d)
if err != nil {
log.Error().Err(err).Msg("Error Copying the File")
}
io.ReadAll reads from the r.Body until an error or EOF and returns the data it read. This means that the entire file is read into memory before it is written to the disk. For smaller files, this might be okay. But what if now we need to upload a 1GB file? What if we have to handle more concurrent request? This surely will consume a lot of memory and no server will be enough to handle that.
io.Copy for more efficient memory usage
The important thing to note is that we don’t need to wait for the entire file to be fully uploaded before we start writing it to the disk. Data is just a stream of bytes, and we can write it to the disk as soon as we receive the chuncked of data.
One trick is to use io.Copy to copy the content of the r.Body directly to the file. Instead of reading the entire content all at once, io.Copy reads the content of the r.Body in chunks and writes it to the file. This way, we can reduce the memory footprint of the server significantly.
Now, you can replace the io.ReadAll and calls to f.Write only with io.Copy:
n, err := io.Copy(f, r.Body)
if err != nil {
log.Error().Err(err).Msg("Error Copying the File")
}
With this change, the io.Copy manages its internal buffer, reads the content of the r.Body in chunks, and writes it to the file as soon as the buffer is full. This way, the amount of memory used now is limited to the size of its internal buffer, not the size of the file being uploaded.
In case where you need a specific requirement to set the size of the buffer, you can use io.CopyBuffer instead. io.CopyBuffer allows you to specify the size of the buffer that you want to use. For more detail, you can check the official documentation.
Now, let’s run the server again and try to upload the same 80MB file multiple times. You should see that the memory consumption of the server is now stable and not increasing significantly.
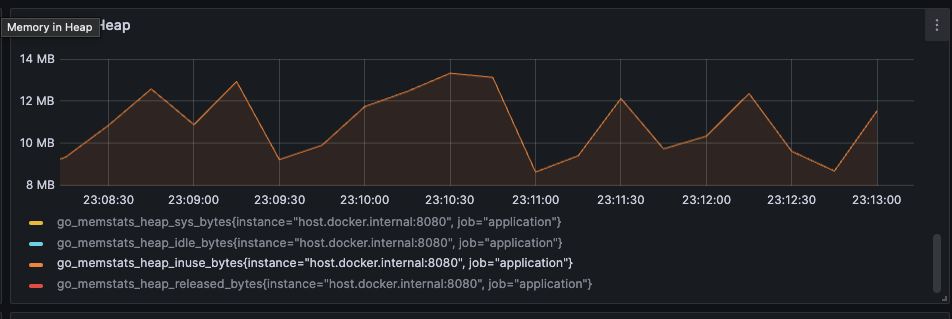
Nice! While we are able to handle the same file size, the memory consumption now is way better than before.
In the next lesson, to ensure that server is not handling very large file in a request, we will see how we can limit the size of the file that can be uploaded to the server.